Data labeling services
The Institute for Research on Digital Organization and Economy (RIDE) is a research unit that develops and implements solutions related to the digital economy, artificial intelligence (AI), and data governance. With the mission of promoting AI application in Vietnam, RIDE provides professional data labeling services for organizations, businesses, and projects developing machine learning models, helping to transform raw data into structured, clean data that is ready for AI training.
Features of the RIDE labeling service
High accuracy and consistency: The labeling process is designed with multi-level validation, including cross-checking, random assessments, and loop feedback, ensuring that the output data meets the quality standards for training AI models.
Integration of smart tools: RIDE develops and operates the data labeling management platform DLMS, which supports automated processes, performance statistics, and anomaly alerts. The AI-integrated system provides label suggestions to optimize costs and time.
Real-time quality management: All labeling actions are recorded, monitored, and analyzed by user, helping the inspection team accurately assess the productivity and reliability of each collaborator.
Multidisciplinary expert team: RIDE collaborates closely with universities to engage students and faculty in the relevant data fields (language, engineering, medicine, agriculture, manufacturing...). This helps ensure that the data is accurately labeled in terms of content, context, and specialized terminology.
Strictly comply with international data security standards: All projects are implemented within the framework of compliance with data protection regulations and privacy rights of each region:
- Vietnam: Decree 13/2023/ND-CP on personal data protection, Cybersecurity Law 2018.
- European Union (EU): General Data Protection Regulation (GDPR).
- United States: Compliance with CCPA (California Consumer Privacy Act) and NIST principles on data management.
- South Korea: Complying with PIPA standards (Personal Information Protection Act).
- Japan: Compliance with APPI (Act on the Protection of Personal Information)
- All personnel involved in the project sign a non-disclosure agreement (NDA) and work on a role-based access control system.

Types of data processed by RIDE
- Image and video data: Object recognition, segmentation, action labeling, product quality inspection.
- Text data: Topic classification, entity extraction (NER), sentiment analysis, semantic labeling, and dialogue.
- Audio data: Speech recognition (ASR), emotion labeling, conversation, and context in multi-regional Vietnamese.
- Specialized data: Technical labeling in the fields of agriculture, healthcare, education, manufacturing industry, public administration
Data Labeling Process at RIDE
1
Survey and analyze input data
Evaluate data quality, define model training objectives. Agree on scope and costs.
2
Design of the labeling process and sample data framework
Establish detailed guidelines for each type of data to ensure a consistent labeling process
3
Data labeling according to standard procedures
Implemented by a team of staff and collaborators trained in specialized topics
4
Quality assurance and feedback handling
Perform probability checks, cross-checks, and handle customer feedback
5
Standardized data handover
The output data is provided in the requested format (JSON, CSV, XML, etc.) along with a quality report.

Support systems and tools
RIDE Data Labeling Management System (DLMS) Platform:
- Permission management, progress monitoring, performance statistics.
- Support for various labeling types: bounding box, polygon, keypoint, entity extraction, text classification.
- Integrating AI-assisted labeling tools helps accelerate the process.
A secure and flexible working environment that can be deployed in an on-premise or cloud model based on customer needs.
The open connection API facilitates easy integration with the partner's AI training system.

The distinguishing feature of RIDE's labeling quality
RIDE collaborates with many domestic universities to train and mobilize a team of students specialized in labeling according to their fields, ensuring that each project has personnel who understand the content of the data (for example: agriculture students label crop data, medical students label X-ray images…).
The collaborators are trained according to the standardized skill framework for data labeling of RIDE, which includes technical skills, cross-checking, and information security.
Some typical projects
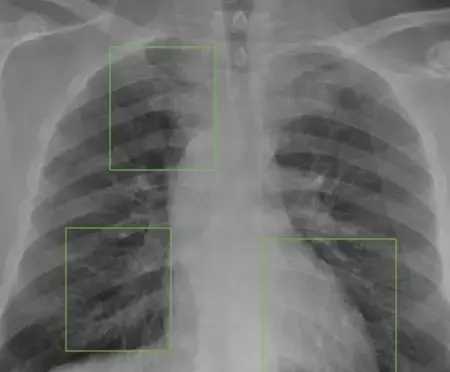
Labeling X-ray diagnostic images
Collaborate with instructors, medical students, and radiology specialists to label areas of lesions, tumors, or signs of inflammation
Some typical projects
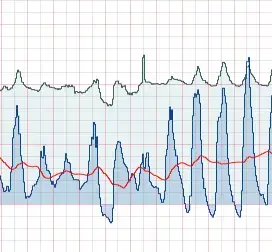
Predictive maintenance
Label sound signals, vibrations from machinery, and parameters from IoT devices to train a model for early fault prediction.
Some typical projects

Text and study material analysis
Label the content of the curriculum, lectures, and questions to build a suggestion model for creating infographics for digital learning materials
Some typical projects

Automatic grading support
Clean and label the dataset of essay exams, supporting the training of automatic scoring models and evaluating proficiency in the literature subject
Some typical projects

Identifying vehicles that violate the law
Label images and videos to train the system for recognizing license plates and automatically detecting traffic violations.
Some typical projects

Application of AI in border gate access control
Training data for the facial recognition system, license plates of some Asian countries, multi-factor identity verification.
Some typical projects

Identifying behavior in public areas
Labeling video from surveillance camera systems to train models for detecting abnormal behavior, large gatherings, or violence.
Some typical projects
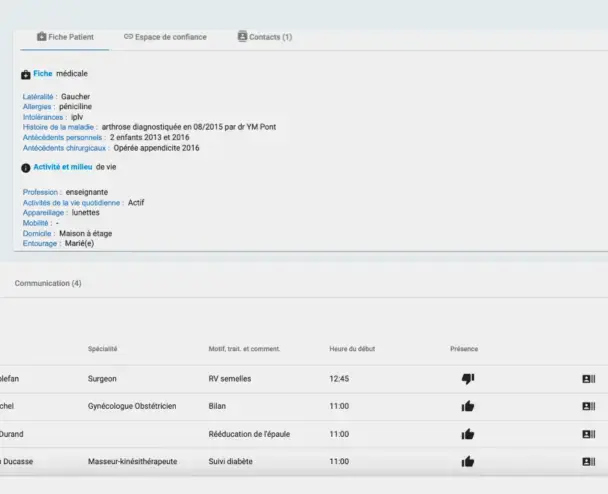
Classification of electronic medical records
Cleaning and labeling medical text for training a model to extract medical entities (drugs, diseases, clinical indicators).
Some typical projects

Virtual health assistant
Labeling conversation data between patients and doctors to train AI models for safe and accurate medical communication.
Some typical projects

Identification of surface defects in mechanical products
Labeling images from the industrial camera inspection line to detect cracks, misalignments, and scratches on the product.
Contact us